In this post I’d like to show a simple integration between Oracle Data Integrator and SQL Server Analysis Services that enables a SSAS cube or dimension to be processed from inside ODI packages.
Motivation
In medium and large environments, companies tend to use tools from one vendor only. This approach have its benefits as built-in integration – mostly of the time – between tools and a single point of support. Moreover, find skilled workers that can handle with tools from same vendor stack is easier.
Although the scenario described above is probably the best case, sometimes companies choose to use solutions from others vendors to deal with specific issues. Therefore, in these situations some questions like lack of integration and tools that overlap some of its features may arise.
The Solution
Though some configurations in ODI and SSAS must be done in order to get the integration, it basically consists in a ODI procedure coded in Jython that does a http request to SSAS passing a xmla script.
First we need to enable SSAS to accept xmla request over http. I won’t show how to to this, but you can get more information at MSDN or just google “configure http access to analysis services”.
Note that when configuring authentication type for the IIS application, it must be set to anonymous and a user account should be used to impersonate the connection. This account will be used later to set up processing-cubes permissions in SSAS databases.
For security reasons, the account used to configure IIS application must have only process permissions, so we need to create a role in SSAS database and allow it to process all cubes and dimensions. Leave the Access and Local Cube / Drillthrough both set to None and check Process for all cubes in database. After that, just add the user account used earlier as a member of this role.

If you plan to use more the one environment you will need to configure one web application for each of them.
Second step is to configure ODI. This is not mandatory, but if you have more than one environment, like QA and Production, it will help you coping deployment questions when migrating from one environment to another.
The ODI configuration lies just in creating a flexfield for contexts where we should place the url where the SSAS responds to http requests. Therefore, in an ODI QA environment you can set the url to call a SSAS instance used only for test or QA purpouses. When the package is deployed at production level, the flexfield context in this environment should be configured with the url pointing to the production instance of SSAS.
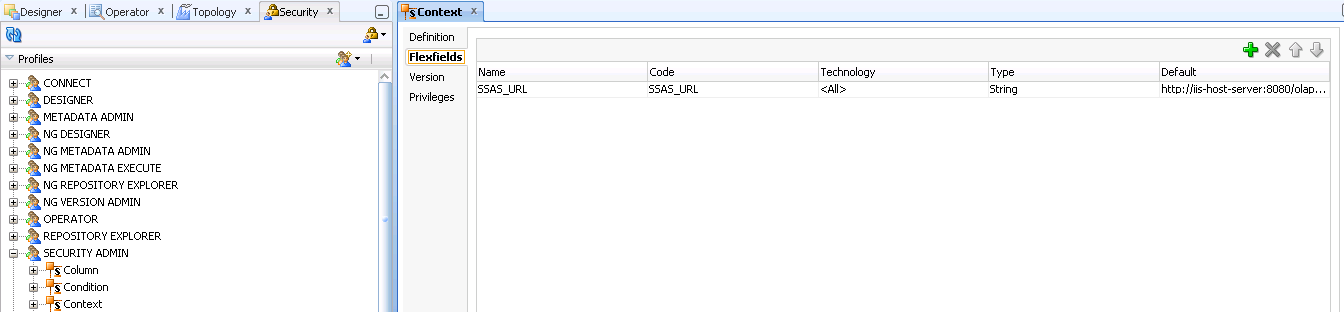
After create the flexfield you can configure it with the SSAS url:

The procedure code is simple. It just wraps a xmla script and completes it with the database and cube names and the processing option.
import urllib
import urllib2
url = '<%=odiRef.getContext("SSAS_URL")%>'
data = '' +
'' +
'' +
'' +
'' +
'' +
'' +
'<%=snpRef.getOption("Processing Option")%> ' +
'UseExisting ' +
' ' +
' ' +
' ' +
' ' +
' '
http_headers = {"Content-Type":'text/xml; charset="UTF-8"; application/xml', 'SOAPAction':'urn:schemas-microsoft-com:xml-analysis:Execute'}
request_object = urllib2.Request(url, data, http_headers)
response = urllib2.urlopen(request_object)
html_string = response.read()
if len(html_string) != 367 :
raise html_string
Now just drop the procedure into a ODI scenario and configure the Options with your own information:
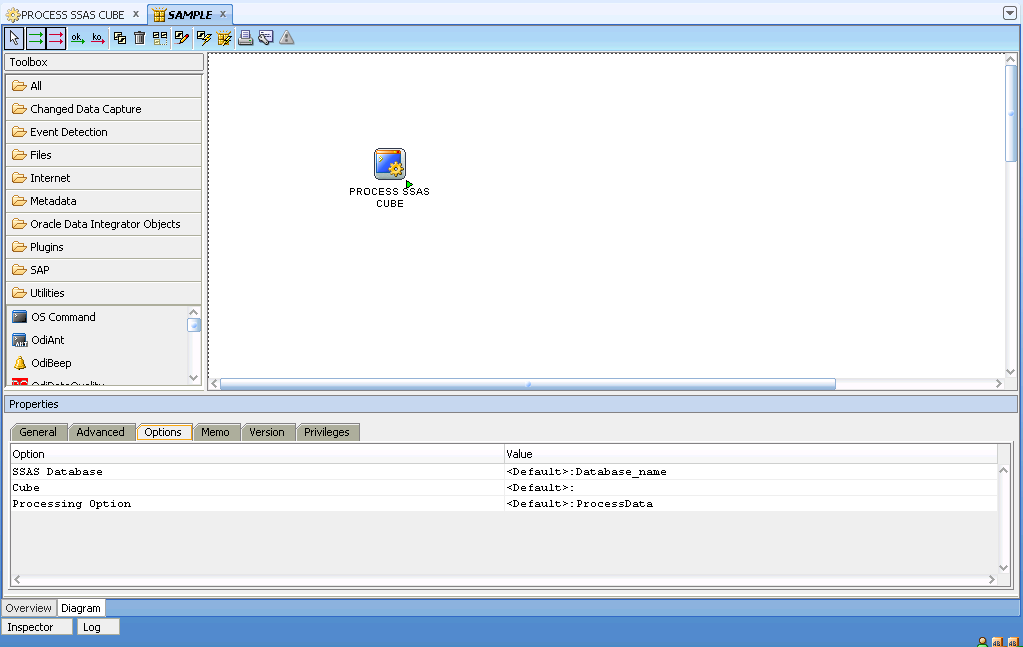
That’s it! Now you can use ODI to process SSAS objects. Below you can download the procedures to process both Cubes and Dimensions. Download ODI Procedures
I would like to thanks my colleague Guthierry Marques who helped us develop these procedures. Thanks buddy!
Working primarily with software development, this is the second time I am working in a Business Intelligence project and since the first time I missed some techniques and processes that I was used to.
Things like source control/revision, automated deployment and tests aren’t common in a BI project. Most of the testing is done by hand, so imagine a bunch of records, thousands to millions and all the validation using excel or another manual approach to compare tables status. Hopefully in another post I’ll talk about automating tools for testing in a BI enviroment.
In my first BI project, I had used another BI solution and code control wasn’t able and migration/deployment was basically copy and paste the xml content from one enviroment to another. Now working in a Analysis Service project I decided to give a try to Team Foudation Service (The TFS online version) to see if we could bring to the project some of these techniques used in software development. Team Foudantion Service can be used free of charge with a team up to 5 members and you can create as many projects you like.
Setting up Tools
First you need an Outlook account to create a TFS workspace at Team Foundation Service, after that you can start creating projects.
Now you need to download and install (if you didn’t have done it yet) SQL Server Data Tools 2012 and Team Explorer for Visual Studio 2012.
Creating Project
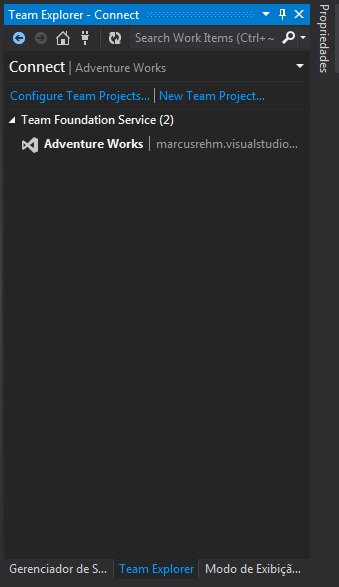
After installing the tools Team Explorer Tab is avaiable inside Data Tools. Click on “New Team Project” to create a project on Team Foudation Service.
With the project created you can go to Solution Tab, right click on solution file and click “Add Project to Source Control” and then do the first Check In.
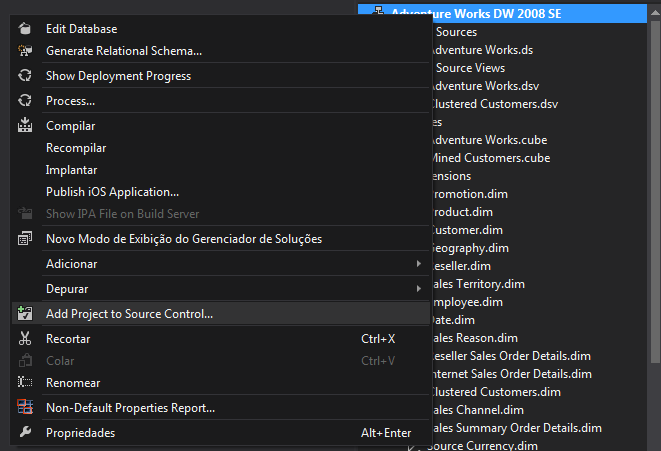
When the proccess finish you’ll have your project controlled by TFS with all the goodies of a source control system.
Navigating to the Project TFS site, clicking on the CODE tab you can see all project files just commited.
More on Team Foundation Service
Source Control is just one thing you can use to support team development, TFS comes with three kinds of project management methodologies templates ready to use with your new source versioned project. Work Items (Project Tasks) can be associated with source code at Check In providing trace information about which changes in source code are related to each task.
