 medium.com/@abderrahmane.roumane.ext?source=rss-f87146cf795f------2
medium.com/@abderrahmane.roumane.ext?source=rss-f87146cf795f------2
Créez une Application de Grille de Mots avec Python : Une Introduction Simple à l’Informatique

Introduction
Dans cet article, nous allons explorer la création d’une application de grille de mots avec Python. Ce projet est parfait pour les débutants souhaitant se familiariser avec la programmation et les concepts de base comme l’extraction et la comparaison de mots.
Objectifs de l’Application
L’application “Word Grid App” permet aux utilisateurs de créer une grille de lettres, d’extraire des mots valides de cette grille et de rechercher des mots possibles à partir d’un ensemble de lettres.
Structure du Projet
Notre projet est structuré de manière à séparer le code, les données et les tests :
- word_grid_app : Contient le code source de l'application.
- data : Contient les fichiers de données nécessaires.
- tests : Contient les tests pour vérifier le bon fonctionnement de l'application.
Création de la Grille de Mots
Nous utilisons la bibliothèque Tkinter pour créer une interface utilisateur simple. Voici un extrait de code pour initialiser la grille :
import tkinter as tk
class WordGridApp:
def __init__(self, root):
self.root = root
self.grid = []
self.setup_grid()
def setup_grid(self):
for i in range(5): # une grille de 5x5 par exemple
row = []
for j in range(5):
entry = tk.Entry(self.root, width=2, font=('Arial', 18))
entry.grid(row=i, column=j)
row.append(entry)
self.grid.append(row)
root = tk.Tk()
app = WordGridApp(root)
root.mainloop()
Extraction des Mots Valides
Pour extraire les mots valides, nous comparons les lettres de la grille avec un dictionnaire de mots. Voici un exemple de fonction pour vérifier si un mot est valide :
def is_valid_word(word, dictionary):
return word in dictionary
# Exemple d'utilisation
dictionary = {'cat', 'dog', 'bird'}
word = 'cat'
print(is_valid_word(word, dictionary)) # Output: True
Comparaison et Recherche de Mots
Nous pouvons rechercher tous les mots possibles formés par les lettres de la grille en utilisant une approche de backtracking :
def find_words(grid, dictionary):
found_words = set()
def backtrack(x, y, path, current_word):
if (x, y) in path or not (0 <= x < len(grid) and 0 <= y < len(grid[0])):
return
current_word += grid[x][y]
if current_word in dictionary:
found_words.add(current_word)
path.add((x, y))
for dx, dy in [(-1, 0), (1, 0), (0, -1), (0, 1)]:
backtrack(x + dx, y + dy, path, current_word)
path.remove((x, y))
for i in range(len(grid)):
for j in range(len(grid[0])):
backtrack(i, j, set(), '')
return found_words
# Exemple d'utilisation
grid = [
['c', 'a', 't'],
['d', 'o', 'g'],
['b', 'i', 'r']
]
dictionary = {'cat', 'dog', 'bird', 'cot'}
print(find_words(grid, dictionary)) # Output: {'cat', 'dog'}
Complétion de Mots Avant et Après
Outre la complétion des mots à partir d’un préfixe, nous pouvons également compléter des mots à partir de suffixes. Cela permet de trouver des mots qui peuvent se terminer par une séquence donnée de lettres.
Complétion de Mots par Préfixe
La complétion de mots par préfixe permet de trouver tous les mots dans le dictionnaire qui commencent par une séquence de lettres spécifique.
def prefix_completions(prefix, dictionary):
completions = [word for word in dictionary if word.startswith(prefix)]
return completions
# Exemple d'utilisation
dictionary = {'cat', 'caterpillar', 'dog', 'door', 'dorm'}
prefix = 'cat'
print(prefix_completions(prefix, dictionary)) # Output: ['cat', 'caterpillar']
Complétion de Mots par Suffixe
De même, la complétion de mots par suffixe permet de trouver tous les mots dans le dictionnaire qui se terminent par une séquence de lettres donnée.
def suffix_completions(suffix, dictionary):
completions = [word for word in dictionary if word.endswith(suffix)]
return completions
# Exemple d'utilisation
suffix = 'dog'
print(suffix_completions(suffix, dictionary)) # Output: ['dog']
Explication du Code
- Fonction prefix_completions : Cette fonction filtre les mots du dictionnaire qui commencent par le préfixe donné.
- Fonction suffix_completions : Cette fonction filtre les mots du dictionnaire qui se terminent par le suffixe donné.
- Utilisation de Compréhensions de Liste : Les deux fonctions utilisent des compréhensions de liste pour itérer sur le dictionnaire et trouver les mots correspondants.
Conclusion
Créer une application de grille de mots avec Python est une excellente manière de s’initier à la programmation. Ce projet couvre des concepts essentiels comme la manipulation des chaînes de caractères, la recherche et l’interface utilisateur avec Tkinter. La complétion de mots avant et après enrichit l’expérience utilisateur et aide à découvrir de nouveaux mots à partir de séquences de lettres spécifiques. N’hésitez pas à explorer davantage et à ajouter des fonctionnalités comme l’enregistrement des scores ou la personnalisation de la grille !
GitHub - aroumanepro/word_grid_app
Comprendre les algorithmes de tri en Informatique : Théorie et mise en pratique
Bienvenue dans le monde fascinant des algorithmes de tri ! Ces processus ingénieux sont bien plus que de simples outils informatiques, ils sont au cœur de la façon dont nous organisons, analysons et utilisons les données dans presque tous les aspects de la technologie moderne. Du tri de vos e-mails à l’organisation des résultats de recherche sur Internet, les algorithmes de tri jouent un rôle discret mais crucial dans notre quotidien numérique.
Dans cet article, nous allons plonger dans les mécanismes et les subtilités de quelques-uns des algorithmes de tri les plus fondamentaux en informatique. Nous explorerons non seulement leur théorie et leur logique sous-jacente, mais nous verrons aussi comment ces principes sont mis en œuvre concrètement à travers des exemples en Python.
Tri à bulles (Bubble Sort)
Explication mathématique :
Le tri à bulles fonctionne en comparant répétitivement des paires adjacentes d’éléments dans un tableau et en les échangeant si elles sont dans le mauvais ordre. Ce processus se répète jusqu’à ce que plus aucun échange n’est nécessaire, ce qui signifie que le tableau est trié. La complexité temporelle moyenne et dans le pire des cas est O(n²), où n est le nombre d’éléments.

def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
C’est simple :
Le tri à bulles, c’est le B.A.-BA du tri. Super pour comprendre les principes de base, même si ce n’est pas une fusée en termes de vitesse. Il est parfait pour des petites listes ou quand on débute. En gros, c’est le tri sympa et sans prise de tête pour les tâches pas trop compliquées.
Tri rapide (Quick Sort)
Explication mathématique :
Le tri rapide est un algorithme “diviser pour régner”. Il sélectionne un élément comme pivot et partitionne le tableau autour du pivot. Le tri rapide a une complexité temporelle moyenne de O(n log n) et une complexité dans le pire des cas de O(n²).
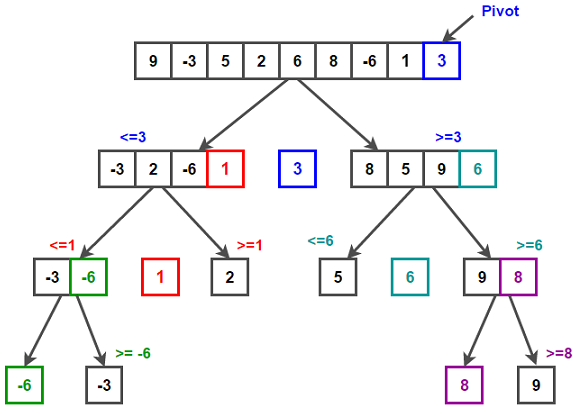
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
Pratique et efficace :
Le tri rapide, c’est le pro du tri. Il sait comment s’y prendre avec les gros volumes de données. Il découpe le problème en morceaux gérables, et hop, il s’en occupe. Un choix solide pour des performances sérieuses, mais attention à bien gérer le pivot pour éviter les ralentissements.
Tri par fusion (Merge Sort)
Explication mathématique :
Le tri par fusion divise récursivement le tableau en deux moitiés, trie chacune d’elles, puis les fusionne. Il a une complexité temporelle constante de O(n log n), ce qui le rend efficace pour les grands tableaux.
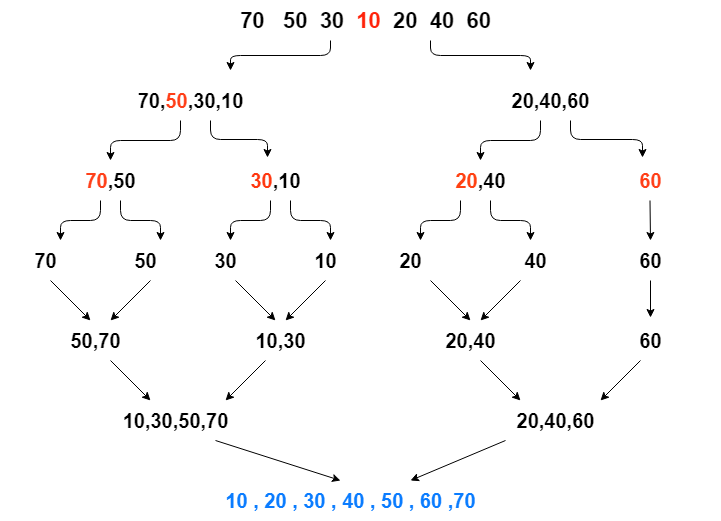
def merge_sort(arr):
if len(arr) > 1:
mid = len(arr) // 2
L = arr[:mid]
R = arr[mid:]
merge_sort(L)
merge_sort(R)
i = j = k = 0
while i < len(L) and j < len(R):
if L[i] < R[j]:
arr[k] = L[i]
i += 1
else:
arr[k] = R[j]
j += 1
k += 1
while i < len(L):
arr[k] = L[i]
i += 1
k += 1
while j < len(R):
arr[k] = R[j]
j += 1
k += 1
return arr
Le tri méthodique :
Le tri par fusion, c’est le tri pour les situations où on a besoin de rigueur. Il découpe, trie et fusionne. C’est un peu comme un chef qui prépare sa recette avec soin. Idéal pour des listes importantes, même s’il prend un peu plus de place. Si vous avez de l’espace et besoin d’efficacité, c’est une bonne option.
Tri par Insertion (Insertion Sort)
Explication mathématique :
Le tri par insertion est un algorithme simple qui construit le tableau final (ou la liste) un élément à la fois. Il est beaucoup moins efficace sur les listes volumineuses que des algorithmes plus avancés tels que le tri rapide, le tri à tas, ou le tri par fusion. Cependant, il a plusieurs avantages : il est simple, il ne nécessite pas d’espace supplémentaire et il est très efficace pour les listes déjà presque triées.
Le principe est de prendre chaque élément du tableau, un par un, et de l’insérer à la bonne place parmi les éléments déjà triés. La complexité temporelle moyenne et dans le pire des cas est O(n²), où n est le nombre d’éléments.
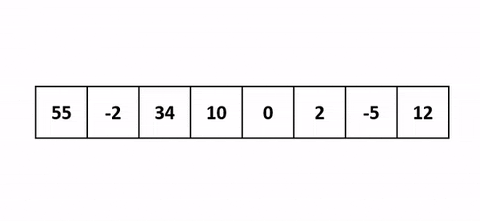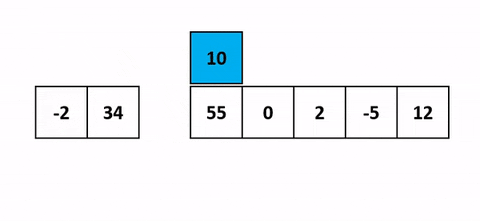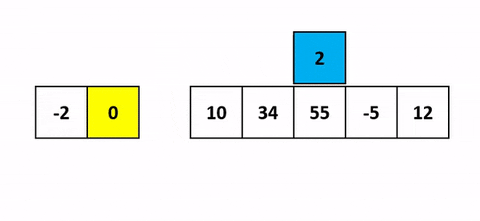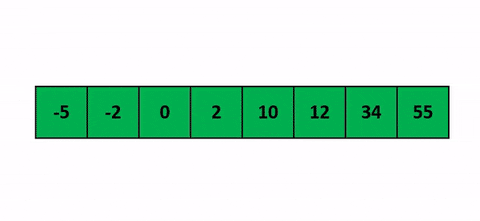
def insertion_sort(arr):
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and key < arr[j]:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
return arr
arr = [12, 11, 13, 5, 6]
insertion_sort(arr)
print("Le tableau trié est :", arr)
Bien pour les petits boulots :
Le tri par insertion est super pour les listes pas trop grandes ou presque triées. Il prend chaque élément et le place où il doit aller, un peu comme ranger des livres sur une étagère. C’est un tri efficace pour des tâches modestes et il a l’avantage de ne pas compliquer les choses.
Conclusion
L’univers des algorithmes de tri est vaste et riche en variété. Nous avons exploré quelques-uns des principaux acteurs — le tri à bulles pour sa simplicité, le tri rapide pour sa vitesse, le tri par fusion pour sa rigueur, et le tri par insertion pour ses applications sur les petits ensembles de données. Cependant, il est important de se rappeler que ce ne sont que quelques exemples parmi un large éventail d’algorithmes disponibles.
En effet, il existe d’autres algorithmes de tri, chacun avec ses propres caractéristiques uniques. Parmi ceux-ci, on peut citer :
- Tri par sélection (Selection Sort) : Simple mais généralement plus lent que les algorithmes comparables.
- Tri par tas (Heap Sort) : Utilise une structure de données de tas pour trier les éléments.
- Tri coquille (Shell Sort) : Une amélioration du tri par insertion, efficace pour des tailles de liste intermédiaires.
- Tri par comptage (Counting Sort) : Un algorithme non comparatif, efficace pour trier des nombres dans une petite plage.
- Tri par base (Radix Sort) : Également non comparatif, excellent pour les nombres ou les chaînes de caractères.
- Tri à peigne (Comb Sort) : Amélioration du tri à bulles, éliminant les tortues (petits éléments près de la fin du tableau).
Chacun de ces algorithmes offre des avantages dans certaines situations, et le choix de l’un plutôt que de l’autre dépend de plusieurs facteurs comme la nature des données à trier, les contraintes de performance, et la complexité algorithmique souhaitée.
En définitive, bien que nous ayons illustré les principes des algorithmes de tri les plus courants, la compréhension de la diversité et de la spécificité de chaque algorithme de tri est essentielle pour toute personne s’engageant dans l’informatique et le développement logiciel. Ces outils sont les piliers sur lesquels repose une grande partie de notre traitement des données, et leur connaissance approfondie est un atout précieux pour tout professionnel du domaine.
Python et Data Mining : Auto-Encodeurs — Cas d’usage 1 : Techniques de compression et décompression d’Images

Configuration de l’environnement Python
Avant de commencer à coder, il est essentiel de configurer un environnement Python propre. Cela implique la création d’un fichier requirements.txt qui liste toutes les bibliothèques nécessaires pour ce projet. Ces bibliothèques incluent scikit-learn pour les algorithmes d'apprentissage automatique, numpy pour la manipulation avancée des tableaux, et Pillow (PIL) pour le traitement d'images. Vous devez installer ces dépendances via pip, l'outil de gestion de paquets pour Python, en exécutant pip install -r requirements.txt dans votre terminal ou invite de commande. Cela garantira que toutes les fonctions nécessaires sont accessibles lorsque vous exécutez votre script.
Pour commencer, créez un fichier requirements.txt avec les dépendances suivantes :
scikit-learn
numpy
pillow
Installez-les en utilisant la commande suivante :
pip install -r requirements.txt
Chargement et préparation de l’image
Le traitement d’image en Python est facilité par l’utilisation de la bibliothèque Pillow. Commencez par charger une image en utilisant la méthode open de la classe Image. Après avoir chargé l'image, vous pouvez la redimensionner pour réduire la complexité du modèle et accélérer le processus d'entraînement de l'auto-encodeur. En redimensionnant l'image, vous pouvez également expérimenter avec différentes résolutions pour voir comment cela affecte la performance de la compression.
Utilisez la bibliothèque Pillow pour charger votre image :
from PIL import Image
image = Image.open('./input_image/image_path.jpeg')
Redimensionnez l’image à une résolution plus petite pour réduire la complexité :
img_resized = image.resize((256, 160))
Transformation en tableau Numpy et prétraitement
Après le redimensionnement, l’image doit être transformée en un tableau Numpy. Cette étape est cruciale car elle convertit l’image, qui est un objet de pixels, en une structure de données que le modèle d’apprentissage automatique peut comprendre et traiter. Vous aplatissez l’image en un tableau 1D tout en conservant les trois canaux RGB. Ensuite, il est important de normaliser les valeurs des pixels afin qu’elles se situent dans une plage numérique qui convient mieux aux algorithmes d’apprentissage automatique, généralement entre -1 et 1.
Flatten l’image en un tableau numpy unidimensionnel :
import numpy as np
image_np = np.array(img_resized).reshape(-1, 3)
Utilisez MinMaxScaler pour normaliser les valeurs des pixels entre -1 et 1 :
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(-1, 1))
image_np_normalized = scaler.fit_transform(image_np)
Configuration et entraînement de l’auto-encodeur
L’auto-encodeur est un type de réseau de neurones utilisé pour apprendre une représentation (codage) pour un ensemble de données, généralement dans le but de réduire la dimensionnalité. Ici, vous configurez un MLPRegressor, qui est une forme d'auto-encodeur, en définissant la taille de la couche cachée. Cette taille détermine la dimensionnalité de l'espace de caractéristiques dans lequel l'image sera compressée. La configuration de l'auto-encodeur, y compris le choix de la fonction d'activation, de l'algorithme de résolution, du taux d'apprentissage et du nombre maximal d'itérations, affecte directement la qualité de la compression et de la reconstruction de l'image.
Configurez l’auto-encodeur avec une seule couche cachée pour la compression :
from sklearn.neural_network import MLPRegressor
hidden_layer_sizes = (128,)
auto_encoder = MLPRegressor(hidden_layer_sizes=hidden_layer_sizes,
activation='tanh',
solver='adam',
learning_rate_init=0.01,
max_iter=10000)
Entraînez l’auto-encodeur en utilisant l’image normalisée comme données d’entraînement :
auto_encoder.fit(image_np_normalized, image_np_normalized)
Compression et décompression de l’image
Une fois l’auto-encodeur entraîné, il peut être utilisé pour compresser l’image en passant les données normalisées à la méthode predict. Cela produit une version compressée de l'image qui est ensuite décompressée (ou reconstruite) par le même modèle. Cette étape illustre la capacité de l'auto-encodeur à capturer l'essentiel de l'information de l'image d'origine tout en réduisant la dimensionnalité.
Utilisez l’auto-encodeur pour prédire (c’est-à-dire décompresser) l’image :
X_predicted = auto_encoder.predict(image_np_normalized)
Post-traitement et sauvegarde de l’image
La dernière étape consiste à transformer les prédictions de l’auto-encodeur en une image. Cela nécessite une inversion du processus de normalisation suivi d’une restructuration du tableau 1D en un tableau 3D avec les dimensions de hauteur, de largeur et de canaux de couleur. Il est essentiel de s’assurer que les valeurs des pixels sont dans la plage admissible pour une image (entre 0 et 255) avant de sauvegarder le résultat. Finalement, l’image originale et la version reconstruite sont enregistrées sur le disque pour une comparaison ultérieure.
Transformez les données dénormalisées en une image :
X_predicted = scaler.inverse_transform(X_predicted)
reconstructed_image = X_predicted.reshape(img_resized.size[1], img_resized.size[0], 3)
reconstructed_image = np.clip(reconstructed_image, 0, 255).astype('uint8')
reconstructed_image = Image.fromarray(reconstructed_image)
Sauvegardez l’image originale et l’image reconstituée :
image.save('./output_image/original_image.png')
reconstructed_image.save('./output_image/reconstructed_image.png')Exemple
https://medium.com/media/61419efd95ebc30c15039ba79e42903b/hrefCode source : GitHub
Ce tutoriel détaille chaque étape du processus de compression et de reconstruction d’une image à l’aide d’un auto-encodeur. Il est conçu pour fournir une compréhension claire de la manière dont les différents composants interagissent et comment le code peut être utilisé pour réaliser une tâche complexe de manière efficace. Cependant, il est important de noter que la qualité de la reconstruction de l’image peut varier en fonction de divers facteurs, y compris la taille de l’image d’entrée, la résolution choisie pour le redimensionnement, et les paramètres de l’auto-encodeur. Des expérimentations et des ajustements peuvent être nécessaires pour obtenir les meilleurs résultats possibles.
Introduction
Node.js est conçu sur un modèle d’entrées/sorties asynchrones non bloquantes, ce qui le rend efficace pour les opérations I/O. Au cœur de ce modèle se trouve la boucle d’événements (Event Loop). Ce tutoriel vous aidera à comprendre comment fonctionne l’Event Loop et comment vous pouvez écrire du code qui tire parti de ce modèle de conception.
Prérequis
- Connaissance de base de JavaScript
- Node.js installé sur votre machine
- Un éditeur de texte pour écrire du code
Introduction à l’Event Loop
Qu’est-ce que l’Event Loop?
Dans un environnement Node.js, l’Event Loop est une boucle d’exécution qui gère les événements ou les callbacks de manière asynchrone. Node.js, étant orienté vers les opérations d’entrée/sortie, utilise ce modèle pour exécuter du code, collecter et traiter les événements et exécuter les sous-tâches. L’avantage de ce modèle est qu’il permet à Node.js de réaliser des opérations I/O sans bloquer le thread principal, ce qui rend l’application beaucoup plus efficace et réactive.
Fonctionnement de l’Event Loop
L’Event Loop travaille de concert avec la pile d’appels (Call Stack), la file d’attente des messages (Message Queue) et d’autres composants tels que le heap pour gérer de manière efficace les opérations asynchrones dans Node.js.
La pile d’appels (Call Stack)
Quand un script Node.js s’exécute, il charge d’abord tout le code dans la Call Stack. C’est là que s’exécutent vos fonctions appelées de manière synchrone. Si une fonction est asynchrone, comme une opération I/O, elle est envoyée à un composant spécialisé (comme le système de fichiers pour les opérations sur les fichiers), et la fonction continue son exécution.
La file d’attente des messages (Message Queue)
Lorsque l’opération asynchrone est terminée, le callback correspondant est ajouté à la Message Queue. Si la Call Stack est vide (c’est-à-dire que toutes les fonctions synchrones ont terminé leur exécution), l’Event Loop pousse le premier callback de la Message Queue vers la Call Stack pour qu’il soit exécuté.
Les phases de l’Event Loop
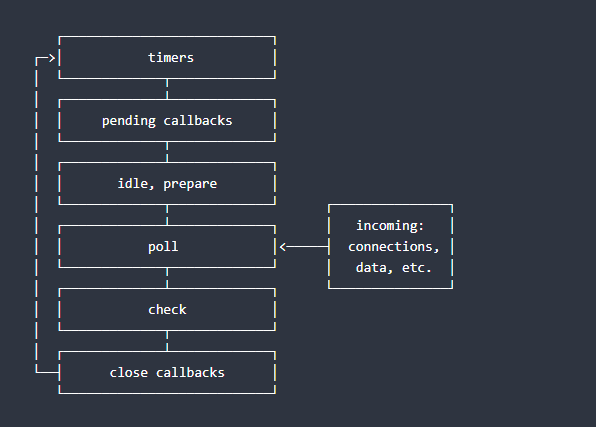
L’Event Loop a plusieurs phases, telles que les timers (où les callbacks de setTimeout ou setInterval sont exécutés), les I/O callbacks, les phases de polling (où il attend les callbacks à exécuter), check (où setImmediate est exécuté), close callbacks, etc. Chaque phase a sa propre file d'attente de callbacks qui sont traités dans l'ordre FIFO (First In, First Out).
Le diagramme suivant donne un aperçu simplifié de l’ordre des opérations de la boucle d’événements.
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
En résumé, l’Event Loop est un mécanisme fondamental dans l’exécution des programmes Node.js. C’est lui qui permet à Node.js de gérer de nombreuses opérations simultanément, malgré le fait qu’il s’exécute sur un seul thread. Une compréhension solide de l’Event Loop et de son fonctionnement est cruciale pour développer des applications Node.js performantes et fiables.
Exemple Simple
Dans cette section, nous allons explorer un exemple basique qui démontre l’asynchronisme en Node.js et l’interaction avec l’Event Loop.
Mise en place de l’environnement
Assurez-vous que Node.js est bien installé sur votre machine. Ouvrez votre terminal et tapez node -v pour vérifier la version installée. Vous devriez obtenir un retour similaire à v16.13.0, indiquant que Node.js est prêt à être utilisé.
Ouvrez votre éditeur de texte ou votre IDE préféré et créez un nouveau fichier event-loop-example.js.
Écrire un script qui utilise setTimeout
Dans votre fichier event-loop-example.js, tapez le code suivant :
console.log('Premier message');
setTimeout(() => {
console.log('Ce message provient de la timeout function');
}, 2000);
console.log('Deuxième message');Ce script va afficher le premier message, ensuite il va définir une fonction de rappel (callback) avec setTimeout qui sera appelée après un délai de 2000 millisecondes, puis immédiatement après, il affichera le deuxième message.
Comprendre l’exécution du script
Enregistrez votre fichier et exécutez-le dans le terminal en utilisant la commande node event-loop-example.js.
Vous observerez l’ordre suivant dans la sortie :
Premier message
Deuxième message
Ce message provient de la timeout function
Malgré le fait que setTimeout a été appelé avant le Deuxième message, son callback n'est exécuté qu'après que tous les autres messages synchrones ont été affichés. Cela illustre le fonctionnement non bloquant de Node.js.
Explication
Voici ce qui se passe dans les coulisses :
- console.log('Premier message') est appelé et exécuté immédiatement.
- setTimeout est appelé. Node.js programme le callback pour s'exécuter dans 2000 ms et continue son exécution sans attendre.
- console.log('Deuxième message') est appelé et exécuté immédiatement.
- La Call Stack est maintenant vide. Node.js vérifie la Message Queue. Comme les 2000 ms ne sont pas encore écoulés, le callback de setTimeout n'est pas encore ajouté à la Message Queue.
- Une fois les 2000 ms passés, le callback est placé dans la Message Queue.
- L’Event Loop, voyant que la Call Stack est vide, prend le callback de la Message Queue et l’exécute.
Ce simple exemple met en évidence le caractère non bloquant de l’Event Loop et comment Node.js peut continuer à traiter d’autres instructions sans attendre que les opérations asynchrones, comme les timeouts ou les opérations I/O, soient complétées. Cela rend Node.js particulièrement performant pour les applications nécessitant de gérer un grand nombre d’opérations asynchrones simultanément.
Interaction avec l’Event Loop
L’Event Loop est essentiel dans le développement d’applications Node.js, car il influence la manière dont nous écrivons et gérons le code asynchrone. Dans cette section, nous allons explorer comment interagir directement avec l’Event Loop pour gérer les tâches asynchrones, et comment éviter de bloquer la boucle avec des opérations longues.
Écrire un code bloquant
D’abord, nous allons voir un exemple de code bloquant. Créez un fichier blocking-code-example.js et ajoutez le code suivant :
console.log('Début du script');
// Opération bloquante simulant une grosse tâche synchrone
const startTime = Date.now();
while (Date.now() - startTime < 1000) {
// boucle pendant 1 seconde
}
console.log('Fin du script');Exécutez ce script avec node blocking-code-example.js et vous remarquerez que le message Fin du script n'apparaît qu'après une seconde. Pendant ce temps, Node.js ne peut rien faire d'autre. Dans une application réelle, ceci pourrait par exemple empêcher le serveur de répondre à des requêtes entrantes.
Utilisation de process.nextTick et setImmediate
Maintenant, modifiez le fichier précédent ou créez-en un nouveau appelé nexttick-setimmediate-example.js pour voir la différence entre process.nextTick() et setImmediate().
console.log('Début du script');
// Planifie une callback à exécuter immédiatement sur la prochaine itération de l'Event Loop
setImmediate(() => {
console.log('Exécution immédiate');
});
// Planifie une callback à exécuter à la fin de cette phase de l'Event Loop
process.nextTick(() => {
console.log('Exécution nextTick');
});
console.log('Fin du script');Lorsque vous exécutez ce script, vous observerez que Exécution nextTick est affiché juste après Fin du script et avant Exécution immédiate. Cela est dû au fait que process.nextTick() met la callback à exécuter après la phase en cours de l'Event Loop (et avant de passer à la phase suivante), alors que setImmediate() planifie l'exécution pour la phase de vérification (check phase) de la boucle d'événements.
Bonnes pratiques
Pour interagir efficacement avec l’Event Loop, gardez à l’esprit ces bonnes pratiques :
- Évitez les opérations bloquantes : Utilisez des fonctions asynchrones fournies par Node.js ou par des bibliothèques tierces pour éviter de bloquer l’Event Loop.
- Décomposez les grosses tâches : Si vous avez une tâche lourde à exécuter, essayez de la décomposer en plusieurs petites tâches ou utilisez le module worker_threads de Node.js pour exécuter le code en parallèle.
- Utilisez les Promesses et async/await : Cela permet d’écrire un code asynchrone plus lisible et évite les pièges courants des fonctions de rappel (callback hell).
Interagir avec l’Event Loop nécessite de comprendre comment Node.js exécute le code asynchrone. En suivant les bonnes pratiques et en utilisant les outils fournis par Node.js, vous pouvez écrire des applications rapides, efficaces et capables de gérer un grand nombre d’opérations simultanées.
Bonnes pratiques
Quand on travaille avec l’Event Loop en Node.js, adopter de bonnes pratiques est crucial pour maintenir la performance et la fiabilité de l’application. Voici quelques stratégies pour tirer le meilleur parti de l’Event Loop.
Asynchronisme non bloquant :
- La règle d’or en Node.js est d’éviter le code bloquant à tout prix. L’utilisation de fonctions asynchrones permet à l’Event Loop de rester ouvert pour d’autres événements et callbacks pendant que les opérations I/O ou d’autres tâches longues sont en cours.
Découpage des tâches lourdes :
- Des tâches intensives CPU peuvent être divisées en petites portions qui peuvent être exécutées de façon séquentielle à travers plusieurs ticks de l’Event Loop, ou en parallèle en utilisant les Workers si cela est nécessaire. Ceci assure que l’Event Loop reste réactif.
Promesses et Async/Await :
- L’utilisation des promesses et de la syntaxe async/await aide à écrire un code asynchrone clair et structuré, en évitant le phénomène souvent appelé “callback hell”.
Gestion d’erreur :
- Gérer les erreurs correctement dans les opérations asynchrones est essentiel pour prévenir des crashs inattendus. Les promesses doivent avoir des gestionnaires de rejet, et les fonctions de rappel doivent vérifier les erreurs en premier lieu.
Profilage et Surveillance :
- Utilisez des outils de profilage et de surveillance pour comprendre comment votre application interagit avec l’Event Loop. Des outils tels que le module async_hooks ou des solutions externes peuvent fournir des informations précieuses sur la santé de l'Event Loop.
Optimisation des opérations I/O :
- Privilégiez des opérations I/O non bloquantes et utilisez des bibliothèques qui supportent l’I/O parallèle pour maximiser l’utilisation des ressources système.
Événements et Écouteurs :
- Assurez-vous de ne pas ajouter un nombre excessif d’écouteurs pour un même événement, ce qui pourrait conduire à des fuites de mémoire. Utilisez removeListener pour nettoyer lorsque c'est nécessaire.
Débogage :
- Développez des compétences solides en débogage. Apprendre à utiliser le débogueur intégré de Node.js ou des outils comme Node Inspector peut grandement aider à comprendre le flux d’exécution du code asynchrone.
Tests :
- Testez votre code asynchrone de manière approfondie. Utilisez des cadres de tests qui prennent en charge les opérations asynchrones pour garantir que chaque partie de votre code se comporte comme prévu.
La compréhension approfondie de l’Event Loop et l’adoption de ces bonnes pratiques sont fondamentales pour le développement d’applications Node.js performantes. Cela vous permettra de construire des systèmes réactifs et évolutifs tout en évitant les pièges courants associés à l’asynchronisme.
Débogage de l’Event Loop
Le débogage de l’Event Loop dans Node.js peut être un défi, étant donné la nature asynchrone et non bloquante de l’environnement d’exécution. Néanmoins, il existe des techniques et des outils qui peuvent vous aider à comprendre et à résoudre les problèmes liés à l’Event Loop.
Outils de débogage
Node.js Inspector :
- Utilisez node --inspect pour démarrer votre application avec le débogueur activé. Cela vous permet de connecter un client de débogage, comme Chrome DevTools, pour inspecter le flux de code, mettre des points d'arrêt, et suivre la pile d'appels.
Visualisation de l’Event Loop :
- Des outils comme clinic.js fournissent une visualisation de l'Event Loop et peuvent montrer où des goulots d'étranglement pourraient se produire.
Logging :
- Le logging est crucial pour comprendre l’état de l’application. Utilisez des bibliothèques de logging pour marquer les étapes clés de l’exécution des opérations asynchrones.
Techniques de débogage
Surveiller la pile d’appels :
- Pendant le débogage, surveillez la pile d’appels (Call Stack) pour voir quelle fonction a été appelée avant d’entrer dans une fonction asynchrone. Cela peut souvent vous aider à comprendre le chemin emprunté par votre programme.
Utiliser les Promesses :
- L’utilisation des promesses avec async/await rend le code plus lisible et plus simple à déboguer. Les erreurs peuvent être capturées et traitées plus efficacement grâce aux blocs try/catch.
Diagnostiquer les fuites de mémoire :
- Des fuites de mémoire peuvent survenir si l’Event Loop est surchargé par trop d’écouteurs d’événements ou des références non nettoyées. Utilisez des outils comme memwatch ou heapdump pour diagnostiquer et trouver la source des fuites.
Points d’arrêt conditionnels
- Placez des points d’arrêt conditionnels qui ne se déclenchent que si certaines conditions sont remplies. Cela peut être utile lorsque vous essayez de déboguer un problème qui ne se produit que dans certaines circonstances.
Async Hooks
- Le module async_hooks de Node.js permet de suivre les ressources asynchrones tout au long de leur cycle de vie. Il peut être utilisé pour comprendre l'ordre des opérations asynchrones et pour repérer des comportements inattendus.
Bonnes pratiques de débogage
- Prenez des mesures progressives : Commencez par des vérifications simples avant de passer à des techniques de débogage plus complexes.
- Isoler le problème : Essayez de reproduire le problème dans un environnement contrôlé pour réduire la complexité et isoler la cause.
- Comprenez le code : Assurez-vous de comprendre les promesses, les callbacks, et l’Event Loop lui-même avant de plonger dans le débogage.
- Revue de code : Parfois, un second regard sur le code par un autre développeur peut aider à identifier rapidement le problème.
Le débogage de l’Event Loop est un aspect avancé du développement en Node.js. En maîtrisant les outils et techniques de débogage et en adoptant de bonnes pratiques, vous pouvez rapidement identifier et résoudre les problèmes, rendant ainsi vos applications Node.js plus robustes et fiables.
Conclusion
Tout au long de cet article, nous avons exploré les mécanismes internes et les pratiques recommandées pour travailler avec l’Event Loop de Node.js, un composant central de son modèle de programmation asynchrone non bloquant.
Récapitulatif des points clés :
- Introduction à l’Event Loop : Nous avons commencé par introduire l’Event Loop, expliquant comment il permet à Node.js de gérer efficacement les opérations asynchrones et d’optimiser la performance dans un environnement à thread unique.
- Exemple Simple : À travers un exemple pratique, nous avons illustré comment l’Event Loop traite les tâches asynchrones, en mettant en lumière la distinction entre le code synchrone et asynchrone.
- Interaction avec l’Event Loop : Nous avons examiné des fonctions spécifiques comme process.nextTick et setImmediate, qui permettent d'interagir avec différentes phases de l'Event Loop et comment elles influencent l'ordre d'exécution des opérations.
- Bonnes pratiques : Des conseils sur comment éviter le blocage de l’Event Loop, l’utilisation de l’asynchrone non bloquant, la gestion appropriée des erreurs et l’optimisation des opérations I/O ont été discutés pour écrire des applications performantes et fiables.
- Débogage de l’Event Loop : Des outils et des stratégies de débogage ont été présentés pour aider à identifier et à résoudre les problèmes liés à l’Event Loop, un aspect crucial pour maintenir la santé de toute application Node.js.
L’importance de l’Event Loop : L’Event Loop est le cœur battant des applications Node.js. Comprendre son fonctionnement est indispensable pour développer des applications capables de gérer un volume élevé de requêtes simultanées sans compromettre les performances.
Enfin, l’Event Loop incarne la philosophie de Node.js : un système efficace et non bloquant capable d’exécuter des tâches asynchrones avec une efficacité maximale. En adoptant les bonnes pratiques et en utilisant les outils de débogage disponibles, les développeurs peuvent s’assurer que leur application exploite toute la puissance offerte par Node.js.
Pour les développeurs soucieux de construire des applications Node.js solides et évolutives, une compréhension approfondie de l’Event Loop n’est pas simplement un atout — c’est une nécessité.

Introduction
Dans un univers informatique où la complexité des systèmes ne cesse de croître, structurer son code devient une quête perpétuelle pour tout développeur en quête d’excellence. C’est dans cette optique que la Clean Architecture s’érige comme un phare dans la nuit, guidant les programmeurs vers des eaux plus sereines de la maintenabilité et de l’évolutivité. Conçue par Robert C. Martin, cette approche vise à organiser le code de manière à le rendre à la fois flexible et résilient face aux changements.
L’essence de la Clean Architecture réside dans sa capacité à séparer les différentes préoccupations d’une application, réduisant ainsi le couplage entre les composants et facilitant les tests. Elle encourage une dépendance minimale à l’égard des Framework et des outils externes, permettant aux règles métier de briller au centre de l’architecture. Mais pourquoi adopter cette approche et comment peut-elle se concrétiser dans vos projets ? C’est ce que nous allons explorer dans cet article.
Nous plongerons au cœur des principes qui fondent la Clean Architecture, nous déchiffrerons sa structure et ses composants, et nous démystifierons les avantages qu’elle promet. Puis, à travers un guide pratique, nous examinerons comment ces théories prennent vie dans le code que nous écrivons au quotidien.
Que vous soyez un fervent adepte des principes SOLID, un étudiant en génie logiciel ou simplement curieux de découvrir de nouvelles méthodologies, ce voyage au sein de la Clean Architecture est conçu pour enrichir votre palette de compétences en développement logiciel. Alors préparez-vous à décoller vers un horizon où le code est propre, ordonné et, surtout, élégamment structuré.
Qu’est-ce que la Clean Architecture ?
Au cœur de l’ingénierie logicielle moderne se trouve un défi de taille : concevoir des applications qui non seulement répondent aux exigences actuelles mais sont aussi préparées pour les évolutions et innovations de demain. C’est ici que la Clean Architecture entre en scène, tel un architecte visionnaire pour le code que nous écrivons.
La Clean Architecture n’est pas simplement une méthode ; c’est une philosophie de conception logicielle qui place les préoccupations métier de l’application au centre de l’attention. Elle se distingue par une organisation du code en couches concentriques, chacune ayant un rôle spécifique et indépendant. Cette structure favorise une dépendance vers l’intérieur, où les couches les plus externes — telles que l’interface utilisateur et les mécanismes de stockage de données — dépendent des couches internes, mais jamais l’inverse. Le résultat est une base de code où le cœur métier reste intact et indépendant des outils extérieurs et des Framework.
Historiquement, la Clean Architecture s’inspire de plusieurs approches antérieures comme l’architecture hexagonale, les couches en oignon et les principes SOLID, toutes prônant la séparation des responsabilités et la souplesse de conception. Le terme lui-même a été popularisé par Robert C. Martin dans son ouvrage de 2012, où il présente cette architecture comme un idéal vers lequel tendre pour un code épuré et robuste.
Les principes fondamentaux de la Clean Architecture s’articulent autour de concepts clés tels que :
- L’indépendance vis-à-vis du Framework : L’architecture ne doit pas dépendre des bibliothèques logicielles. Cela permet de minimiser le coût du changement de Framework et d’assurer une plus grande agilité dans le développement.
- La testabilité : Le système d’entreprise doit être testable sans UI, base de données, serveur web ou tout autre élément externe.
- L’indépendance vis-à-vis de l’UI : L’interface utilisateur peut changer facilement, sans modification majeure du reste du système. Une application web peut devenir une application de bureau sans réécrire la logique métier.
- L’indépendance vis-à-vis de la base de données : La logique métier ne dépend pas du type de base de données utilisée, permettant ainsi un changement aisé de système de stockage.
- L’indépendance des agents extérieurs : La logique métier ne doit pas être affectée par des changements dans des services externes, qu’il s’agisse de serveurs web ou d’autres formes d’interfaces.
Dans les sections suivantes, nous explorerons en détail chacune des couches de la Clean Architecture, leurs interactions, et comment elles s’imbriquent pour former une structure solide et flexible.
Les Composants de la Clean Architecture
La Clean Architecture se compose de plusieurs couches, chacune avec sa propre responsabilité. Comprendre le rôle de chaque composant est essentiel pour maîtriser la mise en œuvre de cette architecture. Examinons les éléments qui constituent cette structure méthodique :
Les Entités (Entities):
- Au cœur de la Clean Architecture se trouvent les entités. Ce sont les objets du domaine métier qui incarnent les règles et cas d’usage les plus généraux de l’application. Les entités sont indépendantes des détails techniques et peuvent être utilisées par toutes les couches de l’application.
Les Cas d’Usage (Use Cases):
- Autour des entités, nous trouvons les cas d’usage. Ils encapsulent toute la logique métier spécifique à l’application. Un cas d’usage décrit une action spécifique que l’utilisateur veut effectuer et les règles métier qui l’encadrent. Il interagit avec les entités et détermine comment les données doivent être transmises entre les entités et les couches extérieures.
Les Adaptateurs d’Interface (Interface Adapters):
- Cette couche, souvent appelée “controllers”, “presenters” ou “gateways”, fait le lien entre les cas d’usage et les couches les plus externes. Elle adapte les données aux formats nécessaires pour les cas d’usage et les présente ensuite dans le format requis par l’interface utilisateur ou d’autres API.
Les Interfaces Utilisateurs (UIs) et les Frameworks et Drivers (Frameworks & Drivers):
- Enfin, la couche externe comprend tout ce qui est en contact avec le monde extérieur, comme l’interface utilisateur, les systèmes de bases de données, les serveurs web, etc. Cette couche est tenue à l’écart des règles métier et sert uniquement à communiquer avec d’autres systèmes ou avec l’utilisateur.
La clé de la Clean Architecture réside dans le respect de la règle de dépendance : toute modification dans les couches externes ne doit pas affecter les couches internes. Les données traversent ces couches via des mécanismes de passage bien définis, souvent à travers des interfaces ou des ports, garantissant que les dépendances circulent uniquement vers l’intérieur.
Dans la pratique, cela signifie que l’on peut modifier l’interface graphique ou la base de données sans perturber la logique métier. De même, on peut réutiliser la logique métier si l’on décide de développer une nouvelle application avec un objectif différent.
La Clean Architecture ne se limite pas à une simple théorie ; elle se manifeste à travers des principes de conception tangibles qui, lorsqu’ils sont appliqués, produisent un code qui est à la fois solide et souple. Elle incarne l’idéal d’un code à l’épreuve du temps, capable de s’adapter et de prospérer dans un écosystème technologique en perpétuelle évolution.
Dans la section suivante, nous aborderons les avantages pratiques et les défis liés à l’implémentation de la Clean Architecture, ainsi que des conseils pour naviguer dans les complexités qui accompagnent ce modèle de conception.
Avantages de la Clean Architecture
L’adoption de la Clean Architecture dans le développement de logiciels peut transformer la manière dont une équipe approche la conception et la maintenance de ses applications. Voici les avantages clés qui en découlent :
Flexibilité et Adaptabilité :
- Avec ses couches bien séparées, la Clean Architecture offre une grande flexibilité. Si un jour une nouvelle technologie ou un nouveau Framework devient prédominant, vous pouvez l’intégrer sans refondre entièrement votre système. Cette adaptabilité est cruciale dans un paysage technologique où le changement est la seule constante.
Indépendance vis-à-vis des technologies :
- En découplant la logique métier des technologies utilisées pour l’interface utilisateur ou l’accès aux données, vous n’êtes plus lié à des choix technologiques spécifiques. Votre code métier reste pur et agnostique, ce qui favorise une meilleure pérennité.
Facilité de Test :
- La séparation nette des préoccupations permet de tester les composants de manière isolée. Les cas d’usage peuvent être validés indépendamment des bases de données ou des interfaces utilisateur, ce qui simplifie considérablement les tests unitaires et d’intégration.
Maintenance et Évolution simplifiées :
- La clarté et l’organisation du code facilitent sa compréhension et sa maintenance. Ajouter de nouvelles fonctionnalités ou modifier des comportements existants devient plus aisé lorsque la logique métier n’est pas enchevêtrée avec le reste de l’infrastructure de l’application.
Déploiement parallèle :
- Les équipes peuvent travailler sur différentes couches simultanément avec un minimum de dépendances croisées. Cela accélère le développement et réduit les conflits entre les équipes travaillant sur différents aspects de l’application.
Sécurité renforcée :
- En isolant la logique métier des influences extérieures, vous réduisez la surface d’attaque potentielle. Les interactions avec des systèmes externes sont contrôlées et peuvent être sécurisées de manière centralisée.
Durabilité du code :
- La Clean Architecture encourage des pratiques qui garantissent que le code reste lisible, compréhensible et donc durable. Cela aide à préserver l’investissement dans le code sur le long terme et facilite le transfert de connaissances au sein des équipes.
Cependant, il est important de noter que l’adoption de la Clean Architecture n’est pas sans défis. La complexité initiale, le temps nécessaire à l’apprentissage et à la mise en œuvre, et la nécessité de discipline en termes de respect des frontières de la couche sont quelques-uns des obstacles à surmonter. Toutefois, les avantages à long terme l’emportent souvent sur ces difficultés initiales.
Dans la section suivante, nous traiterons de ces défis et de la manière de les relever, tout en maximisant les bénéfices de cette approche architecturale dans vos projets de développement logiciel.
Mise en œuvre de la Clean Architecture
La mise en œuvre de la Clean Architecture exige une compréhension approfondie de ses principes ainsi qu’une application rigoureuse de ses directives. Voici des étapes essentielles pour intégrer avec succès cette architecture dans vos projets :
Analyse et Conception Initiales :
- Avant même de penser au code, il est crucial de bien comprendre les exigences du domaine d’application. Identifiez les entités, les règles métier et les cas d’usage qui seront au centre de votre architecture. Cette compréhension initiale est la pierre angulaire d’une application bien architecturée.
Définition des Frontières :
- Établissez clairement les limites entre les différentes couches de votre application. Assurez-vous que les membres de votre équipe comprennent la règle de dépendance qui veut que les couches externes dépendent des couches internes et non l’inverse.
Création des Entités :
- Commencez par développer les entités qui modélisent le domaine métier. Ces entités doivent être des objets simples, sans logique spécifique à un cas d’usage ou dépendance envers des Framework ou des bases de données.
Développement des Cas d’Usage :
- Implémentez la logique métier dans des cas d’usage qui manipulent les entités. Chaque cas d’usage doit représenter un processus métier distinct et être indépendant des détails de l’implémentation externe.
Conception des Adaptateurs :
- Mettez en place des adaptateurs pour convertir les données d’entrée et de sortie en formats utilisables par les cas d’usage et les entités. Les adaptateurs permettent d’isoler la logique métier des détails techniques de l’application.
Intégration des Interfaces Utilisateur et des Drivers :
- Développez l’interface utilisateur, les bases de données, les services web et tout autre composant externe nécessaire à votre application. Ces composants devraient être conçus de manière à s’adapter facilement aux changements grâce à l’utilisation des adaptateurs.
Tests Rigoureux :
- Implémentez une suite de tests robuste qui couvre les entités, les cas d’usage et les interactions entre les couches. L’objectif est de s’assurer que la logique métier fonctionne comme prévu et que les couches externes interagissent correctement avec les cas d’usage.
Révision et Refactorisation :
- À mesure que le projet évolue, il est vital de revoir et de refactoriser le code pour maintenir l’alignement avec les principes de la Clean Architecture. L’objectif est de préserver la séparation des préoccupations et d’éviter le couplage fort.
En suivant ces étapes, vous pouvez assurer une intégration cohérente de la Clean Architecture dans vos projets. Il est important de se rappeler que la transition vers cette architecture peut nécessiter du temps et des efforts considérables, surtout pour les équipes habituées à des approches moins structurées.
La Clean Architecture n’est pas une solution universelle et ne se prête pas à chaque situation. Elle révèle toute sa valeur dans le cadre d’applications complexes où les enjeux de durabilité, de testabilité et de flexibilité sont au premier plan. Pour des projets de moindre envergure ou des prototypes conçus rapidement, une architecture plus simple peut souvent s’avérer suffisante.
Dans la prochaine section, nous discuterons des meilleures pratiques et des pièges à éviter lors de l’adoption de la Clean Architecture, pour garantir que vos efforts portent leurs fruits et que votre code reste propre et évolutif.
Défis et Solutions lors de la mise en œuvre de la Clean Architecture
L’intégration de la Clean Architecture est une entreprise qui n’est pas exempte de défis. Cependant, pour chaque obstacle, il existe des stratégies et des solutions pour les surmonter.
Complexité Perçue :
- Défi : La Clean Architecture peut sembler complexe à première vue, avec ses multiples couches et règles.
- Solution : La formation et l’éducation sont essentielles. Investissez dans des sessions de formation pour vous-même et votre équipe. Utilisez des diagrammes et des exemples concrets pour décomposer la complexité et montrer comment chaque partie s’imbrique dans le tout.
Courbe d’apprentissage :
- Défi : Il peut y avoir une courbe d’apprentissage raide pour les équipes non familières avec les principes de la Clean Architecture.
- Solution : Commencez par de petits projets ou modules pour pratiquer et renforcer les principes. Encouragez le pair programming et les revues de code pour partager les connaissances et les compétences.
Résistance au Changement :
- Défi : Les développeurs peuvent résister au changement, surtout s’ils sont habitués à un certain ensemble de pratiques.
- Solution : Montrez les bénéfices à long terme de la Clean Architecture en termes de maintenance et d’évolutivité. Faites des membres de l’équipe des champions du changement en impliquant tout le monde dans le processus de décision.
Sur-ingénierie :
- Défi : Il peut être tentant de trop concevoir ou d’introduire une complexité inutile en suivant les principes de la Clean Architecture.
- Solution : Restez pragmatique. Appliquez les principes de la Clean Architecture là où ils apportent de la valeur. Utilisez une approche itérative pour évaluer et ajuster la conception au fur et à mesure.
Intégration avec des Systèmes Externes :
- Défi : L’intégration de systèmes externes qui ne suivent pas les mêmes principes peut être problématique.
- Solution : Utilisez des adaptateurs et des façades pour encapsuler l’intégration externe, gardant ainsi la logique métier isolée et protégée des détails d’implémentation des systèmes tiers.
Performance :
- Défi : Certaines personnes craignent que les multiples couches puissent nuire à la performance.
- Solution : Profilerez et mesurez les performances réelles plutôt que de supposer. Les optimisations prématurées sont souvent inutiles. Lorsque des problèmes de performances surviennent, adressez-les avec des stratégies ciblées.
Maintien de la Discipline :
- Défi : Maintenir la discipline nécessaire pour suivre les règles de la Clean Architecture peut être difficile, surtout sous pression.
- Solution : Intégrez des contrôles de qualité dans votre processus de CI/CD. Mettez en place des outils de linting et d’analyse statique pour renforcer les bonnes pratiques.
En abordant ces défis de front et en mettant en œuvre des solutions pragmatiques, la transition vers la Clean Architecture peut être lissée, permettant à votre équipe de récolter les fruits d’une base de code plus propre, plus maintenable et plus évolutive.
Exemple de Clean Architecture en TypeScript
Pour démontrer les principes de la Clean Architecture dans un contexte pratique, je vais vous fournir un exemple de code simplifié en TypeScript. L’exemple suivant illustre une petite partie de ce que pourrait être une application respectant la Clean Architecture, en mettant l’accent sur la séparation des préoccupations.
Imaginez que nous avons une application qui gère les utilisateurs. Nous allons créer une structure de dossiers qui reflète les différentes couches de la Clean Architecture.
src/
|-- entities/
| `-- User.ts
|-- use_cases/
| `-- CreateUser.ts
|-- interfaces/
| |-- controllers/
| | `-- UserController.ts
| `-- gateways/
| `-- UserRepository.ts
|-- framework_drivers/
`-- web/
`-- ExpressServer.ts
Entities (Entités)
// src/entities/User.ts
export class User {
constructor(
public readonly id: string,
public readonly name: string,
public readonly email: string
) {}
}
Use Cases (Cas d’utilisation)
// src/use_cases/UserUseCases.ts
import { User } from "../entities/User";
import { UserRepository } from "../interfaces/gateways/UserRepository";
export class UserUseCases {
constructor(private userRepository: UserRepository) {}
async createUser(name: string, email: string): Promise{
const user = new User(this.generateId(), name, email);
await this.userRepository.add(user);
return user;
}
async getUserById(userId: string): Promise{
return this.userRepository.findById(userId);
}
async updateUser(userId: string, updateParams: { name?: string; email?: string }): Promise{
const user = await this.userRepository.findById(userId);
if (!user) {
throw new Error('User not found');
}
user.name = updateParams.name || user.name;
user.email = updateParams.email || user.email;
await this.userRepository.update(user);
return user;
}
async deleteUser(userId: string): Promise{
await this.userRepository.delete(userId);
}
private generateId(): string {
// Implementation for ID generation, could be a UUID or similar
return '...';
}
}
Interface Adapters (Adaptateurs d’Interface)
// src/interfaces/gateways/UserRepository.ts
import { User } from "../../entities/User";
export interface UserRepository {
add(user: User): Promise;
findById(userId: string): Promise;
update(user: User): Promise;
delete(userId: string): Promise;
}
// src/interfaces/controllers/UserController.ts
import { CreateUser } from "../../use_cases/CreateUser";
import { Request, Response } from "express";
export class UserController {
constructor(private createUserUseCase: CreateUser) {}
async createUser(req: Request, res: Response) {
const { name, email } = req.body;
try {
const user = await this.createUserUseCase.execute(name, email);
res.json(user);
} catch (error) {
// Gestion des erreurs
res.status(500).json({ error: error.message });
}
}
}
Frameworks & Drivers (Cadres et Pilotes)
// src/framework_drivers/web/ExpressServer.ts
import express from 'express';
import { UserController } from '../../interfaces/controllers/UserController';
const app = express();
app.use(express.json());
const userController = new UserController(/* Dépendances */);
app.post('/users', (req, res) => userController.createUser(req, res));
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
Conclusion
La Clean Architecture propose une vision structurée et disciplinée du développement logiciel, conçue pour favoriser la création de systèmes évolutifs et maintenables. En plaçant les règles métier au cœur de l’architecture, elle facilite la création de logiciels qui peuvent non seulement s’adapter aux exigences changeantes mais aussi survivre à l’évolution des Framework et des modes technologiques.
Toutefois, comme nous l’avons exploré, l’adoption de la Clean Architecture n’est pas sans défis. Elle exige un engagement envers une formation continue, une volonté de s’adapter et de changer de pratiques établies, ainsi qu’une approche pragmatique pour éviter la sur-ingénierie. Les bénéfices, cependant, justifient les efforts : une base de code plus propre, une plus grande flexibilité face aux changements, et une meilleure testabilité.
En fin de compte, la Clean Architecture n’est pas seulement un ensemble de directives pour structurer le code, c’est une philosophie de développement qui privilégie la clarté, la séparation des préoccupations et la durabilité. En intégrant ces principes dans votre travail, vous pouvez non seulement améliorer la qualité de vos applications mais aussi renforcer la dynamique de travail de votre équipe.
Comme pour tout modèle architectural, il est important de l’adapter aux spécificités de chaque projet. Il n’y a pas de solution universelle, mais dans le paysage en constante évolution du développement logiciel, la Clean Architecture offre un cadre solide pour naviguer dans la complexité sans se perdre dans les détails.
Livres :
- ”Clean Architecture: A Craftsman’s Guide to Software Structure and Design” par Robert C. Martin
Articles de Blog et Études de Cas :
Les auto-encodeurs en data mining : un guide initiatique et pratique pour débutants
Introduction
Les auto-encodeurs sont des réseaux de neurones artificiels utilisés pour l’apprentissage non supervisé, une forme d’apprentissage où l’on cherche à comprendre et à modéliser la structure sous-jacente des données sans étiquettes explicites.
Concept clé :
Le but principal d’un auto-encodeur est de compresser les données d’entrée et ensuite de les reconstruire aussi précisément que possible. Cette compression est réalisée en apprenant une représentation des données d’entrée dans un espace de dimension réduite, appelé “espace latent”. Imaginez que nous avons une feuille de papier remplie de points; l’auto-encodeur tente de plier cette feuille de manière à rapprocher les points similaires tout en maintenant les groupes de points éloignés les uns des autres.
Pourquoi les auto-encodeurs sont-ils utiles ?
- Réduction de Dimensionnalité : Semblable à PCA (Principal Component Analysis), mais plus flexible car ils peuvent apprendre des représentations non linéaires.
- Compression de Données : Ils peuvent apprendre à compresser les données de manière plus efficace que les méthodes traditionnelles.
- Apprentissage de Caractéristiques : Ils peuvent apprendre à extraire des caractéristiques importantes des données de manière automatique.
- Prétraitement : Ils peuvent servir à nettoyer les données bruyantes avant leur utilisation dans d’autres tâches d’apprentissage automatique.
Les mathématiques fondamentales des auto-encodeurs
Les auto-encodeurs se composent de deux parties principales : l’encodeur et le décodeur.
Encodeur :
L’encodeur prend les données d’entrée x et les transforme en une représentation compressée z, souvent de dimension inférieure. Mathématiquement, cela peut être représenté par une fonction de mappage f :
z = f(x)
Cette fonction est généralement composée de plusieurs couches de neurones, avec des poids W et des biais b, et peut inclure une fonction d’activation non linéaire σ :
z = σ(Wx + b)
Décodeur :
Le décodeur prend la représentation compressée z et tente de reconstruire l’entrée originale x, que nous appellerons x′ pour indiquer qu’il s’agit d’une reconstruction. Ceci est également réalisé par une série de transformations :
x′ = g(z)
où g est une autre série de couches de neurones avec leurs propres poids et biais.
Fonction de perte :
Pour mesurer la qualité de la reconstruction, on utilise une fonction de perte L, qui compare l’entrée x et la sortie reconstruite x′. Une fonction de perte commune est l’erreur quadratique moyenne (MSE) :
L(x,x′) = ∥x − x′∥²
L’objectif de l’apprentissage est de minimiser cette fonction de perte.
Exemples concrets des auto-encodeurs
Les auto-encodeurs, de par leur conception, sont des outils de modélisation de données d’une puissance et d’une flexibilité étonnantes. Pour mieux saisir leur potentiel, nous allons explorer ensemble trois cas d’usage concrets qui illustrent l’efficacité des auto-encodeurs dans des situations variées.
Exemple 1 : Compression de données
Imaginez que vous avez une très grande photo et que vous souhaitez la réduire pour qu’elle prenne moins de place sur votre téléphone, mais sans perdre trop de détails importants. Un auto-encodeur peut apprendre à compresser les données de l’image en une forme plus petite, puis à les décompresser en une image semblable à l’originale. C’est comme apprendre les astuces pour plier un plan de manière intelligente afin qu’il puisse rentrer dans votre poche, mais que vous puissiez toujours le lire une fois déplié.
Exemple 2: Réduction de bruit
Supposons que vous ayez une vieille photo de famille qui a été endommagée au fil du temps, présentant des taches et des rayures. Un auto-encodeur peut être entraîné pour reconnaître ces défauts et les supprimer, tout en conservant les caractéristiques essentielles de l’image. C’est comme si vous aviez un expert en restauration qui sait exactement comment retoucher une peinture pour effacer les dommages sans toucher à l’œuvre d’art elle-même.
Exemple 3: Détection d’anomalies
Imaginez une usine qui produit des milliers de pièces chaque jour, et vous devez trouver rapidement les pièces défectueuses. Un auto-encodeur peut apprendre à quoi ressemble une pièce normale et, lorsqu’une pièce anormale lui est présentée, il ne pourra pas la reproduire correctement, signalant ainsi qu’il y a un problème. Cela fonctionne comme un contrôleur de qualité qui sait reconnaître les écarts par rapport à la norme.
Exemple de code (JavaScript)
L’exemple de code JavaScript présenté ci-dessous démontre l’application d’un auto-encodeur, une forme de réseau de neurones utilisée pour apprendre une représentation codée de données d’entrée. En utilisant un ensemble de données constitué de paires de valeurs binaires, ce script configure et entraîne un auto-encodeur pour reproduire ses entrées à sa sortie. À travers l’initialisation des poids, la propagation avant, le calcul de l’erreur et le réajustement des poids, l’auto-encodeur affine ses paramètres internes sur plusieurs époques. Cela lui permet de créer une représentation interne des données qui peut être utilisée pour reconstruire l’entrée avec une grande précision. Ce processus est illustré étape par étape dans le code, offrant une vision claire de la manière dont un auto-encodeur fonctionne et s’ajuste au fur et à mesure de l’apprentissage.
https://medium.com/media/eee8948ecbd373ccc0719752cae6065b/hrefCode source : GitHub
Exemple de code (Python)
L’exemple de code Python qui suit illustre la mise en œuvre d’un auto-encodeur, qui est un type spécifique de réseau de neurones artificiels destiné à apprendre une représentation condensée des données d’entrée. Ce script met en place un auto-encodeur pour traiter des données binaires par paires, entraînant le modèle à reproduire ses entrées à sa sortie. Le code détaille le processus d’initialisation des poids synaptiques, la propagation avant pour la génération des sorties, la rétropropagation pour le calcul des erreurs et la mise à jour des poids pour minimiser ces erreurs. L’auto-encodeur affine ainsi ses paramètres internes à travers de multiples itérations ou époques d’entraînement, permettant au modèle d’apprendre à coder et décoder les données d’entrée avec précision. Ce processus est détaillé étape par étape dans le code, offrant une explication concrète du fonctionnement d’un auto-encodeur et de son adaptation progressive pendant l’entraînement.
https://medium.com/media/23d8e177ad95c966b59391cd05739ac8/hrefCode source : GitHub
Avec scikit-learn:
L’exemple de code Python ci-dessous démontre l’utilisation de la bibliothèque scikit-learn pour créer et entraîner un auto-encodeur, un type de réseau de neurones utilisé pour apprendre une représentation codée des données. Dans cet exemple, nous utilisons le MLPRegressor, un modèle de réseau de neurones à couches multiples, pour construire l'auto-encodeur. Le script commence par importer les bibliothèques nécessaires et préparer les données. Il initialise ensuite le modèle avec une architecture définie, y compris la taille de la couche cachée correspondant à la dimensionnalité codée. Le modèle est entraîné en utilisant les données d'entrée comme cibles, dans le but de reconstruire les entrées à sa sortie. Après l'entraînement, le script évalue les performances du modèle en calculant la perte sur l'ensemble de données. Cet exemple illustre comment scikit-learn peut être utilisé pour des tâches d'apprentissage automatique complexes telles que l'auto-encodage, avec seulement quelques lignes de code et sans nécessiter une implémentation détaillée des algorithmes de réseau de neurones.
https://medium.com/media/8bddba478b01ca935ca4bef7e6fc0432/hrefCode source : GitHub
Conclusion
Pour conclure, ce guide a été une introduction simplifiée au monde complexe des auto-encodeurs, conçue pour dévoiler les rudiments de cette technologie en surface. À travers cette vulgarisation, nous avons effleuré les principes fondamentaux et les multiples applications des auto-encodeurs dans l’univers captivant du data mining. Nous avons vu comment ces modèles parviennent à capturer et reconstruire l’essence des données avec une fidélité étonnante, même compressées dans un espace restreint.
Les exemples de code en JavaScript et en Python, enrichis par l’usage de la bibliothèque scikit-learn, ont permis de renforcer notre compréhension théorique par la pratique de la programmation. Les ressources mises à disposition sur GitHub invitent à continuer cette exploration et à approfondir la maîtrise de ces outils.

Introduction
Le data mining, ou l’extraction de connaissances à partir de grandes quantités de données, est un domaine fascinant qui permet de découvrir des modèles et des relations cachées dans des ensembles de données complexes. Parmi les techniques utilisées, la règle d’association joue un rôle crucial dans l’analyse des transactions, particulièrement dans le secteur du commerce pour l’analyse du panier de la ménagère. Voici une introduction à ce concept avec une explication mathématique et un exemple de code pour illustrer le processus.
Qu’est-ce qu’une règle d’association?
Une règle d’association est une expression qui identifie des éléments qui apparaissent fréquemment ensemble dans des transactions. Par exemple, dans un supermarché, la règle “Si un client achète du pain et de la moutarde, il est probable qu’il achète aussi des oignons” révèle une relation entre la vente de ces trois produits.
Pour comprendre cette relation, trois concepts clés doivent être définis : le support, la confiance et le lift.
Support
Le support est la fréquence relative d’une combinaison d’items dans l’ensemble de données. Il est calculé comme le nombre de transactions contenant un item (ou un ensemble d’items) divisé par le nombre total de transactions. La formule est :
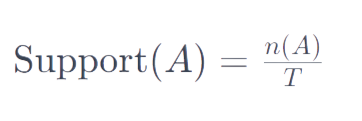
où n(A) est le nombre de transactions contenant l’item A, et T est le nombre total de transactions.
Confiance
La confiance est une mesure de la fiabilité de la règle. Elle est définie comme la fréquence à laquelle les items du côté droit de la règle apparaissent dans les transactions qui contiennent les items du côté gauche. La formule est :
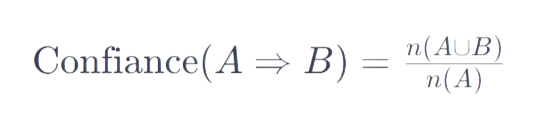
où A⇒B indique la règle “si A, alors B”, n(A∪B) est le nombre de transactions contenant à la fois A et B.
Lift
Le lift est une mesure de la force de la règle. Il compare la probabilité d’observer A et B ensemble avec la probabilité d’observer A et B indépendamment. La formule est :
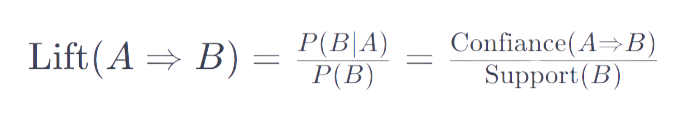
ou, en utilisant les nombres de transactions :
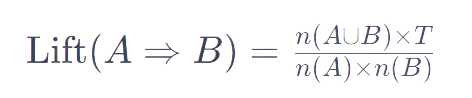
Un lift supérieur à 1 suggère que A et B sont achetés ensemble plus souvent que ce qui serait attendu si ils étaient indépendants; un lift inférieur à 1 suggère le contraire.
Exemples concrets des règles d’association
Pour comprendre les règles d’association, imaginons une situation familière : une épicerie. Chaque fois qu’un client achète des produits, la liste de ces achats est enregistrée. Avec des milliers de clients, l’épicerie accumule une grande quantité de données sur les habitudes d’achat. Voici quelques exemples pour illustrer comment ces données peuvent être utilisées pour trouver des règles d’association significatives.
Exemple 1 : La règle du petit-déjeuner
Supposons que nos données montrent que 100 clients ont acheté du lait, 30 ont acheté du lait et des céréales, et 20 ont acheté du lait, des céréales et du sucre. Si nous fixons notre seuil de support à 10% (c’est-à-dire que l’item doit apparaître dans au moins 10% des transactions), alors la combinaison de lait et céréales est intéressante car elle apparaît dans 30% des cas.
Ensuite, si nous calculons la confiance, qui est la probabilité d’acheter des céréales sachant que le lait a été acheté, nous trouvons 30% (car 30 sur 100 achats de lait contiennent également des céréales). Si la confiance est supérieure à notre seuil (disons 20%), nous considérons cela comme une règle forte. La règle est alors: si un client achète du lait, il y a 30% de chance qu’il achète aussi des céréales.
Pour le lift, qui compare la probabilité d’achat de céréales avec du lait à la probabilité d’achat de céréales seules, supposons que 10% des transactions totales contiennent des céréales. Le lift serait alors de 3 (0.3 / 0.1), indiquant que l’achat de lait augmente la probabilité d’achat de céréales trois fois par rapport à l’achat aléatoire de céréales.
Exemple 2 : La règle des barbecues
Dans un autre scénario, disons que durant l’été, les données montrent une forte association entre l’achat de charbon de bois et de viande grillée. Si le support de l’achat de charbon et de viande est de 15% et que la confiance est de 50%, cela signifie que la moitié des clients qui achètent du charbon achètent également de la viande pour le barbecue. Le lift pourrait révéler que ces articles sont quatre fois plus susceptibles d’être achetés ensemble plutôt que séparément.
Ces exemples nous aident à visualiser comment les règles d’association fonctionnent dans la pratique. Elles sont utiles non seulement pour le marketing et l’approvisionnement mais aussi pour comprendre les comportements des consommateurs.
Exemple de code (JavaScript)
L’exemple de code JavaScript suivant utilise les données des transactions pour générer des règles d’association en fonction d’un seuil de support donné. Il procède par la génération de tous les ensembles d’items uniques, puis il crée des paires et ensembles plus larges en vérifiant si leur support dépasse le seuil. Ensuite, pour chaque combinaison valide, il calcule la confiance et le lift pour déterminer la force de la règle d’association.
https://medium.com/media/67a2aad73c26382333c12e0e6638e840/hrefCode source : GitHub
Ce code illustre le processus itératif de découverte de règles potentielles et de vérification de leur pertinence statistique.
Exemple de code (Python)
L’exemple de code Python suivant utilise les données des transactions pour générer des règles d’association en fonction d’un seuil de support donné. Il commence par générer tous les ensembles d’éléments uniques, puis crée des paires et des ensembles plus grands en vérifiant si leur support dépasse le seuil spécifié. Ensuite, pour chaque combinaison valide, il calcule la confiance et le lift afin de déterminer la force de la règle d’association.
https://medium.com/media/ec951991cfb355ed3947d3b12cbd31db/hrefCode source : GitHub
Avec mlxlend :
L’exemple de code Python suivant utilise la bibliothèque mlxtend pour exploiter les données des transactions afin de générer des règles d'association, en se basant sur un seuil de support prédéfini. Le processus débute par la génération de tous les ensembles d'éléments uniques. À l'aide des fonctions de mlxtend, il crée ensuite des paires et des ensembles plus vastes, tout en vérifiant si leur support dépasse le seuil fixé. Pour chaque combinaison valide identifiée, le code utilise mlxtend pour calculer la confiance et le lift, ce qui permet d'évaluer la solidité de la règle d'association.
https://medium.com/media/43a9f487ddfc0a762062c57573706afe/hrefCode source : GitHub
Conclusion
Les règles d’association sont un outil puissant pour découvrir des relations cachées dans les ensembles de données. Elles permettent aux entreprises de mieux comprendre le comportement des clients et d’optimiser leur stratégie de marketing et de stockage. Avec une compréhension des principes mathématiques et une pratique du code, même les débutants peuvent commencer à exploiter la puissance de cette technique d’analyse de données.
DRY : L’Art de la Non-Répétition en Programmation

Introduction
Le principe DRY (Don’t Repeat Yourself) est une technique de programmation visant la concision, l’efficacité et la maintenabilité du code. En évitant la redondance, on aspire à produire un code optimal et aisément modifiable.
Pourquoi éviter la redondance ?
La duplication de code engendre une consommation inutile de ressources et multiplie les zones de vulnérabilité. Une erreur dans une portion de code dupliquée se propage partout où cette portion est répétée.
Comment appliquer DRY : Exemples Concrets
Si nous prenons l’exemple d’une plateforme e-commerce souhaitant offrir des réductions à ses clients :
1.Méthode non recommandée:
prix_chemise = 50
prix_final_chemise = prix_chemise - (prix_chemise * 0.1)
prix_pantalon = 80
prix_final_pantalon = prix_pantalon - (prix_pantalon * 0.1)
Dans cet exemple, la logique de remise est dupliquée pour chaque produit. Modifier le taux de remise nécessiterait des ajustements à plusieurs endroits, augmentant le risque d’erreurs.
2.Méthode recommandée:
def appliquer_remise(prix, remise):
return prix - (prix * remise)
prix_chemise = 50
remise_etudiant = 0.1
prix_final = appliquer_remise(prix_chemise, remise_etudiant)
Grâce à la fonction appliquer_remise, si le taux de remise change, une seule modification est nécessaire.
Conseils pratiques
Même s’il est essentiel, DRY ne doit pas être appliqué de manière systématique. L’objectif n’est pas d’éliminer toute redondance, mais de déterminer où et comment faire des abstractions appropriées. Évitez de trop abstraire, car cela pourrait rendre le code trop complexe.
Conclusion
Le principe DRY nous encourage à rechercher la simplicité et la clarté dans notre code. En respectant ce principe, nous facilitons la maintenance et l’évolution de nos applications.

Pourquoi SOLID ?
Les principes SOLID sont conçus pour rendre le code plus clair, plus compréhensible et plus facile à modifier. Il ne s'agit pas de règles strictes, mais plutôt de directives pour aider à concevoir un code plus robuste et maintenable. Ils sont particulièrement utiles pour travailler en équipe, où la clarté et la facilité de modification sont cruciales.
Il est important de comprendre que SOLID n'est pas une « loi » de programmation, mais plutôt un ensemble de meilleures pratiques. Vous pouvez rencontrer des cas où il est plus judicieux de ne pas suivre un ou plusieurs de ces principes, mais ces cas sont plutôt l'exception que la règle.
Explication détaillée des principes SOLID
1. Principe de responsabilité unique (SRP)
Pourquoi est-ce important ?
Lorsqu'une classe à plus d'une raison de changer, cela peut rendre le système plus fragile et difficile à comprendre. En isolant les responsabilités, vous rendez le code plus résistant aux bugs et aux effets secondaires inattendus lors des changements.
Comment l'appliquer ?
Réfléchissez à ce qui pourrait changer dans votre application. Par exemple, si vous avez une classe qui gère à la fois la logique métier et la persistance des données, elle aura deux raisons de changer. Séparez ces responsabilités en deux classes distinctes.
Exemple :
Mauvaise pratique :
class User {
constructor(public nom: string, public age: number) {}
save() {
// Code pour sauvegarder l'utilisateur dans une base de données
}
}La classe Userest responsable à la fois de la représentation des données utilisateur et de leur sauvegarde, ce qui enfreint le SRP.
Bonne pratique :
class User {
constructor(public name: string, public age: number) {}
}
class UserDatabase {
save(user: User) {
// Code pour sauvegarder l'utilisateur dans une base de données
}
}La responsabilité de sauvegarder les données est désormais déléguée à la classe UserDatabase, respectant ainsi le SRP.
2. Principe ouvert/fermé (OCP)
Pourquoi est-ce important ?
Si chaque fois qu'une nouvelle fonctionnalité est ajoutée, vous devez modifier le code existant, alors le risque d'introduire des bugs est plus élevé. Ce principe aide à minimiser ce risque.
Comment l'appliquer ?
Utilisez l'héritage et/ou les interfaces pour permettre à votre code d'être extensible sans modification du code existant. Les nouvelles fonctionnalités peuvent être ajoutées en étendant une classe ou en implémentant une interface.
Exemple :
Mauvaise pratique :
class Rectangle {
constructor(public width: number, public height: number) {}
}
function area(shapes: any[]): number {
let total = 0;
for (const shape of shapes) {
if (shape instanceof Rectangle) {
total += shape.width * shape.height;
}
}
return total;
}La fonction areadoit être modifiée chaque fois qu'un nouveau type de forme est ajouté, ce qui enfreint l'OCP.
Bonne pratique :
interface Shape {
area(): number;
}
class Rectangle implements Shape {
constructor(public width: number, public height: number) {}
area(): number {
return this.width * this.height;
}
}
function totalArea(shapes: Shape[]): number {
return shapes.reduce((acc, shape) => acc + shape.area(), 0);
}La fonction totalAreaest maintenant ouverte à l'extension mais fermée à la modification, conformément à l'OCP.
3. Principe de substitution de Liskov (LSP)
Pourquoi est-ce important ?
Violer ce principe peut entraîner des comportements inattendus dans les classes dérivées, ce qui peut à son tour provoquer des bugs difficiles à détecter.
Comment l'appliquer ?
Assurez-vous que les classes dérivées peuvent remplacer la classe de base sans affecter le comportement attendu. N'outrepassez pas une méthode de la classe de base d'une manière qui rompt son contrat, c'est-à-dire sa spécification.
Exemple :
Mauvaise pratique :
class Bird {
fly() {
// ...
}
}
class Penguin extends Bird {
fly() {
throw new Error("Les pingouins ne peuvent pas voler !");
}
}La classe Penguinne peut pas être substituée à Birdsans altérer le comportement attendu, enfreignant ainsi le LSP.
Bonne pratique :
class Bird {
fly() {
// ...
}
}
class FlightlessBird extends Bird {
fly() {
console.log("Je ne peux pas voler.");
}
}
class Penguin extends FlightlessBird {}La classe Penguinpeut maintenant être substituée à Birdsans problème, conformément au LSP.
4. Principe de ségrégation d'interface (ISP)
Pourquoi est-ce important ?
En combrant une interface avec des méthodes inutiles pour certains clients, vous compliquez l'implémentation et augmentez la difficulté de compréhension du système.
Comment l'appliquer ?
Créez des interfaces plus petites et plus spécifiques. Un client ne devrait pas être forcé d'implémenter les méthodes qu'il n'utilise pas.
Mauvaise pratique :
interface Worker {
work(): void;
eat(): void;
}L’interface Workerimpose des méthodes que toutes les classes implémentantes ne doivent nécessairement pas, enfreignant ainsi l'ISP.
Bonne pratique :
interface Eater {
eat(): void;
}
interface Worker {
work(): void;
}Les interfaces Eateret Workersont maintenant plus petites et spécifiques, ce qui respecte l'ISP.
5. Principe d'inversion de dépendance (DIP)
Pourquoi est-ce important ?
Cela minimise le couplage entre les composants de haut niveau et les composants de bas niveau, rendant ainsi le système plus modulaire et plus facile à comprendre et à maintenir.
Comment l'appliquer ?
Inverser les dépendances en se fiant à des abstractions plutôt qu'à des implémentations concrètes. Utilisez l'injection de dépendance pour passer ces abstractions en tant que paramètres aux classes qui en ont besoin.
Mauvaise pratique :
class MySQLDatabase {
connect() {
// ...
}
}
class UserManager {
db = new MySQLDatabase();
}La classe UserManagerest fortement couplée à MySQLDatabase, ce qui enfreint le DIP.
Bonne pratique :
interface Database {
connect(): void;
}
class MySQLDatabase implements Database {
connect() {
// ...
}
}
class UserManager {
constructor(private database: Database) {}
}La classe UserManagerdépend maintenant d'une abstraction, ce qui est conforme au DIP.
Conclusion :
Les principes SOLID offrent un cadre pour développer un code plus propre, plus efficace et plus maintenable. En suivant ces principes, les développeurs peuvent créer des systèmes plus robustes et plus flexibles, tout en probable la probabilité d'introduire des erreurs lors des modifications du code.
- Principe de responsabilité unique (SRP) : Il augmente la cohésion et réduit le couplage, facilitant la gestion des changements.
- Open/Closed Principe (OCP) : Il permet d'étendre le comportement du logiciel sans modifier le code existant, minimisant ainsi les risques d'erreurs.
- Liskov Substitution Principe (LSP) : Il aide à garantir que l'ajout de nouvelles classes dérivées n'entraînera pas d'effets secondaires inattendus.
- Interface Segregation Principe (ISP) : Il améliore la lisibilité et l'organisabilité du code en inévitablement les interfaces surchargées.
- Dependency Inversion Principe (DIP) : Il rend le système plus modulaire et plus facile à tester, en dépendant des abstractions plutôt que des implémentations concrètes.
Bien que ces principes soient des recommandations plutôt que des règles strictes, les ignorer peut entraîner des problèmes de complexité et de maintenabilité à long terme. C'est pourquoi ils sont privilégiés comme des meilleures pratiques dans le domaine du génie logiciel.